Note
Go to the end to download the full example code.
Fused Softmax
In this tutorial, you will write a fused softmax operation that is significantly faster than PyTorch’s native op for a particular class of matrices: those whose rows can fit in the GPU’s SRAM.
In doing so, you will learn about:
The benefits of kernel fusion for bandwidth-bound operations.
Reduction operators in Triton.
Motivations
Custom GPU kernels for elementwise additions are educationally valuable but won’t get you very far in practice. Let us consider instead the case of a simple (numerically stabilized) softmax operation:
import torch
import triton
import triton.language as tl
from triton.runtime import driver
DEVICE = triton.runtime.driver.active.get_active_torch_device()
def is_hip():
return triton.runtime.driver.active.get_current_target().backend == "hip"
def is_cdna():
return is_hip() and triton.runtime.driver.active.get_current_target().arch in ('gfx940', 'gfx941', 'gfx942',
'gfx90a', 'gfx908')
def naive_softmax(x):
"""Compute row-wise softmax of X using native pytorch
We subtract the maximum element in order to avoid overflows. Softmax is invariant to
this shift.
"""
# read MN elements ; write M elements
x_max = x.max(dim=1)[0]
# read MN + M elements ; write MN elements
z = x - x_max[:, None]
# read MN elements ; write MN elements
numerator = torch.exp(z)
# read MN elements ; write M elements
denominator = numerator.sum(dim=1)
# read MN + M elements ; write MN elements
ret = numerator / denominator[:, None]
# in total: read 5MN + 2M elements ; wrote 3MN + 2M elements
return ret
When implemented naively in PyTorch, computing y = naive_softmax(x) for \(x \in R^{M \times N}\)
requires reading \(5MN + 2M\) elements from DRAM and writing back \(3MN + 2M\) elements.
This is obviously wasteful; we’d prefer to have a custom “fused” kernel that only reads
X once and does all the necessary computations on-chip.
Doing so would require reading and writing back only \(MN\) bytes, so we could
expect a theoretical speed-up of ~4x (i.e., \((8MN + 4M) / 2MN\)).
The torch.jit.script flags aims to perform this kind of “kernel fusion” automatically
but, as we will see later, it is still far from ideal.
Compute Kernel
Our softmax kernel works as follows: each program loads a set of rows of the input matrix X strided by number of programs, normalizes it and writes back the result to the output Y.
Note that one important limitation of Triton is that each block must have a power-of-two number of elements, so we need to internally “pad” each row and guard the memory operations properly if we want to handle any possible input shapes:
@triton.jit
def softmax_kernel(output_ptr, input_ptr, input_row_stride, output_row_stride, n_rows, n_cols, BLOCK_SIZE: tl.constexpr,
num_stages: tl.constexpr):
# starting row of the program
row_start = tl.program_id(0)
row_step = tl.num_programs(0)
for row_idx in tl.range(row_start, n_rows, row_step, num_stages=num_stages):
# The stride represents how much we need to increase the pointer to advance 1 row
row_start_ptr = input_ptr + row_idx * input_row_stride
# The block size is the next power of two greater than n_cols, so we can fit each
# row in a single block
col_offsets = tl.arange(0, BLOCK_SIZE)
input_ptrs = row_start_ptr + col_offsets
# Load the row into SRAM, using a mask since BLOCK_SIZE may be > than n_cols
mask = col_offsets < n_cols
row = tl.load(input_ptrs, mask=mask, other=-float('inf'))
# Subtract maximum for numerical stability
row_minus_max = row - tl.max(row, axis=0)
# Note that exponentiation in Triton is fast but approximate (i.e., think __expf in CUDA)
numerator = tl.exp(row_minus_max)
denominator = tl.sum(numerator, axis=0)
softmax_output = numerator / denominator
# Write back output to DRAM
output_row_start_ptr = output_ptr + row_idx * output_row_stride
output_ptrs = output_row_start_ptr + col_offsets
tl.store(output_ptrs, softmax_output, mask=mask)
We can create a helper function that enqueues the kernel and its (meta-)arguments for any given input tensor.
properties = driver.active.utils.get_device_properties(DEVICE.index)
NUM_SM = properties["multiprocessor_count"]
NUM_REGS = properties["max_num_regs"]
SIZE_SMEM = properties["max_shared_mem"]
WARP_SIZE = properties["warpSize"]
target = triton.runtime.driver.active.get_current_target()
kernels = {}
def softmax(x):
n_rows, n_cols = x.shape
# The block size of each loop iteration is the smallest power of two greater than the number of columns in `x`
BLOCK_SIZE = triton.next_power_of_2(n_cols)
# Another trick we can use is to ask the compiler to use more threads per row by
# increasing the number of warps (`num_warps`) over which each row is distributed.
# You will see in the next tutorial how to auto-tune this value in a more natural
# way so you don't have to come up with manual heuristics yourself.
num_warps = 8
# Number of software pipelining stages.
num_stages = 4 if SIZE_SMEM > 200000 else 2
# Allocate output
y = torch.empty_like(x)
# pre-compile kernel to get register usage and compute thread occupancy.
kernel = softmax_kernel.warmup(y, x, x.stride(0), y.stride(0), n_rows, n_cols, BLOCK_SIZE=BLOCK_SIZE,
num_stages=num_stages, num_warps=num_warps, grid=(1, ))
kernel._init_handles()
n_regs = kernel.n_regs
size_smem = kernel.metadata.shared
if is_hip():
# NUM_REGS represents the number of regular purpose registers. On CDNA architectures this is half of all registers available.
# However, this is not always the case. In most cases all registers can be used as regular purpose registers.
# ISA SECTION (3.6.4 for CDNA3)
# VGPRs are allocated out of two pools: regular VGPRs and accumulation VGPRs. Accumulation VGPRs are used
# with matrix VALU instructions, and can also be loaded directly from memory. A wave may have up to 512 total
# VGPRs, 256 of each type. When a wave has fewer than 512 total VGPRs, the number of each type is flexible - it is
# not required to be equal numbers of both types.
NUM_GPRS = NUM_REGS
if is_cdna():
NUM_GPRS = NUM_REGS * 2
# MAX_NUM_THREADS represents maximum number of resident threads per multi-processor.
# When we divide this number with WARP_SIZE we get maximum number of waves that can
# execute on a CU (multi-processor) in parallel.
MAX_NUM_THREADS = properties["max_threads_per_sm"]
max_num_waves = MAX_NUM_THREADS // WARP_SIZE
occupancy = min(NUM_GPRS // WARP_SIZE // n_regs, max_num_waves) // num_warps
else:
occupancy = NUM_REGS // (n_regs * WARP_SIZE * num_warps)
occupancy = min(occupancy, SIZE_SMEM // size_smem)
num_programs = NUM_SM * occupancy
num_programs = min(num_programs, n_rows)
# Create a number of persistent programs.
kernel[(num_programs, 1, 1)](y, x, x.stride(0), y.stride(0), n_rows, n_cols, BLOCK_SIZE, num_stages)
return y
Unit Test
We make sure that we test our kernel on a matrix with an irregular number of rows and columns. This will allow us to verify that our padding mechanism works.
torch.manual_seed(0)
x = torch.randn(1823, 781, device=DEVICE)
y_triton = softmax(x)
y_torch = torch.softmax(x, axis=1)
assert torch.allclose(y_triton, y_torch), (y_triton, y_torch)
As expected, the results are identical.
Benchmark
Here we will benchmark our operation as a function of the number of columns in the input matrix – assuming 4096 rows.
We will then compare its performance against (1) torch.softmax and (2) the naive_softmax defined above.
@triton.testing.perf_report(
triton.testing.Benchmark(
x_names=['N'], # argument names to use as an x-axis for the plot
x_vals=[128 * i for i in range(2, 100)], # different possible values for `x_name`
line_arg='provider', # argument name whose value corresponds to a different line in the plot
line_vals=['triton', 'torch', 'naive_softmax'], # possible values for `line_arg``
line_names=["Triton", "Torch", "Naive Softmax"], # label name for the lines
styles=[('blue', '-'), ('green', '-'), ('red', '-')], # line styles
ylabel="GB/s", # label name for the y-axis
plot_name="softmax-performance", # name for the plot. Used also as a file name for saving the plot.
args={'M': 4096}, # values for function arguments not in `x_names` and `y_name`
))
def benchmark(M, N, provider):
x = torch.randn(M, N, device=DEVICE, dtype=torch.float32)
stream = getattr(torch, DEVICE.type).Stream()
getattr(torch, DEVICE.type).set_stream(stream)
if provider == 'torch':
ms = triton.testing.do_bench(lambda: torch.softmax(x, axis=-1))
if provider == 'triton':
ms = triton.testing.do_bench(lambda: softmax(x))
if provider == 'naive_softmax':
ms = triton.testing.do_bench(lambda: naive_softmax(x))
gbps = lambda ms: 2 * x.numel() * x.element_size() * 1e-9 / (ms * 1e-3)
return gbps(ms)
benchmark.run(show_plots=True, print_data=True)
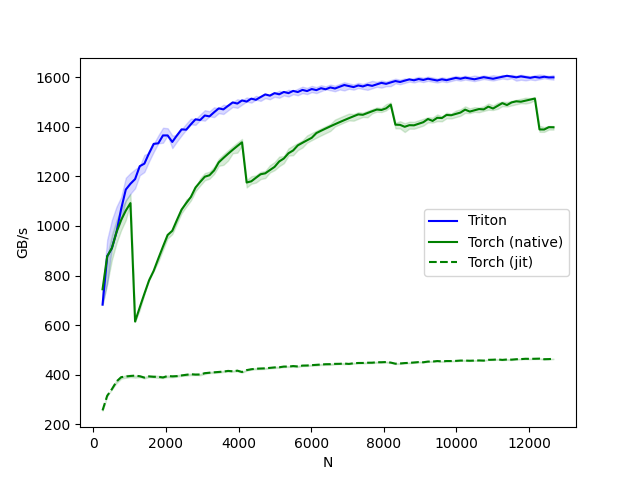
softmax-performance:
N Triton (GB/s) Torch (GB/s) Naive Softmax (GB/s)
0 256.0 504.785698 705.932937 205.244509
1 384.0 709.363118 819.736652 264.142691
2 512.0 824.413423 917.088944 300.813028
3 640.0 832.009134 926.071504 331.807331
4 768.0 912.896200 990.995639 351.348723
5 896.0 980.782085 1039.573887 356.629076
6 1024.0 1031.470162 1080.609196 353.693880
7 1152.0 1023.455357 1066.759697 348.522740
8 1280.0 1072.771575 1103.376616 348.326242
9 1408.0 1114.716931 1137.996756 343.569547
10 1536.0 1145.979004 1165.401704 334.288106
11 1664.0 1181.474272 1187.733048 329.521145
12 1792.0 1203.997413 1193.418308 326.323223
13 1920.0 1231.977515 1219.027231 325.778157
14 2048.0 1256.762989 1252.382535 325.533841
15 2176.0 1181.028847 960.923311 325.632628
16 2304.0 1204.314143 1001.463894 326.950429
17 2432.0 1218.134583 1036.344914 327.050072
18 2560.0 1251.366098 1068.184015 328.635503
19 2688.0 1261.796847 1097.314952 330.049590
20 2816.0 1281.330017 1125.333361 329.704600
21 2944.0 1289.066792 1143.724914 332.188422
22 3072.0 1309.541409 1174.210779 333.910817
23 3200.0 1319.130962 1176.328938 335.304626
24 3328.0 1327.913529 1202.100628 336.596318
25 3456.0 1339.643627 1224.820291 337.107485
26 3584.0 1345.729734 1246.711070 338.672549
27 3712.0 1345.845780 1269.589962 340.386430
28 3840.0 1360.693674 1287.842605 341.083162
29 3968.0 1366.116741 1296.825705 341.130679
30 4096.0 1367.819839 1316.786906 338.937569
31 4224.0 1340.233049 1278.511375 342.907285
32 4352.0 1350.492772 1299.195212 345.280965
33 4480.0 1357.861511 1315.002336 345.760758
34 4608.0 1367.945280 1336.350380 347.184425
35 4736.0 1362.047149 1342.514370 348.304759
36 4864.0 1382.238892 1355.812243 349.287002
37 4992.0 1375.213458 1372.331475 350.473448
38 5120.0 1382.957270 1385.269894 351.137829
39 5248.0 1384.693875 1354.261205 352.091529
40 5376.0 1384.787946 1374.194682 352.221446
41 5504.0 1394.615819 1383.763119 353.731834
42 5632.0 1401.457787 1388.536620 353.594437
43 5760.0 1400.528352 1405.886606 355.335470
44 5888.0 1391.704198 1417.468570 355.250529
45 6016.0 1406.401092 1423.738896 356.829450
46 6144.0 1415.050496 1439.589266 357.422672
47 6272.0 1417.071761 1407.630990 357.862837
48 6400.0 1418.671691 1412.207185 359.022972
49 6528.0 1422.533125 1418.746081 359.220201
50 6656.0 1419.790980 1435.771245 359.282636
51 6784.0 1423.360659 1439.343835 360.379266
52 6912.0 1425.167018 1442.689425 360.606182
53 7040.0 1425.524040 1455.522605 360.934550
54 7168.0 1429.536103 1460.758094 362.245264
55 7296.0 1433.804640 1088.115077 362.896087
56 7424.0 1441.206020 1099.566949 362.731012
57 7552.0 1435.950168 1110.956452 364.079746
58 7680.0 1438.068994 1123.627630 363.614113
59 7808.0 1430.424719 1135.910005 364.571328
60 7936.0 1439.235627 1143.428848 364.759633
61 8064.0 1437.364533 1151.501880 365.502499
62 8192.0 1428.228942 1152.515130 363.741565
63 8320.0 1390.566489 1116.890973 361.431094
64 8448.0 1384.530679 1125.574589 362.327226
65 8576.0 1390.676013 1126.879072 363.241082
66 8704.0 1387.086449 1135.468062 364.676970
67 8832.0 1392.972606 1132.345495 365.093888
68 8960.0 1384.664692 1138.174621 365.878736
69 9088.0 1396.572484 1135.414932 366.329110
70 9216.0 1404.548645 1139.808523 367.406308
71 9344.0 1393.900536 1421.956774 367.309355
72 9472.0 1407.826793 1432.921142 368.855176
73 9600.0 1394.193010 1434.214407 369.033635
74 9728.0 1400.714801 1438.602157 369.541753
75 9856.0 1397.054204 1441.600442 369.368850
76 9984.0 1389.707652 1450.123230 371.048249
77 10112.0 1401.289719 1456.807467 371.270805
78 10240.0 1407.644735 1468.545822 371.469990
79 10368.0 1413.316290 1464.240954 370.281270
80 10496.0 1406.249924 1469.550653 370.537385
81 10624.0 1408.773142 1466.902881 370.623891
82 10752.0 1394.353174 1474.128657 371.016271
83 10880.0 1400.202276 1480.826145 372.037268
84 11008.0 1416.110684 1479.966935 372.708925
85 11136.0 1422.796456 1486.974840 372.730985
86 11264.0 1417.734239 1486.057016 372.682258
87 11392.0 1424.097174 1488.089110 373.451020
88 11520.0 1411.327499 1497.950590 373.803703
89 11648.0 1416.843705 1498.023259 374.140120
90 11776.0 1431.412039 1501.497181 374.518018
91 11904.0 1432.156299 1510.114639 375.148918
92 12032.0 1421.272501 1508.799543 375.245022
93 12160.0 1420.359991 1516.521287 376.094305
94 12288.0 1431.099421 1421.609726 375.055886
95 12416.0 1435.723077 1397.500827 374.279756
96 12544.0 1440.010673 1396.902109 375.590829
97 12672.0 1431.056846 1391.148325 374.356589
- In the above plot, we can see that:
Triton is 4x faster than the Torch JIT. This confirms our suspicions that the Torch JIT does not do any fusion here.
Triton is noticeably faster than
torch.softmax– in addition to being easier to read, understand and maintain. Note however that the PyTorch softmax operation is more general and will work on tensors of any shape.
Total running time of the script: (0 minutes 34.679 seconds)