Note
Go to the end to download the full example code.
Fused Attention
This is a Triton implementation of the Flash Attention v2 algorithm from Tri Dao (https://tridao.me/publications/flash2/flash2.pdf)
Credits: OpenAI kernel team
Extra Credits:
Original flash attention paper (https://arxiv.org/abs/2205.14135)
Rabe and Staats (https://arxiv.org/pdf/2112.05682v2.pdf)
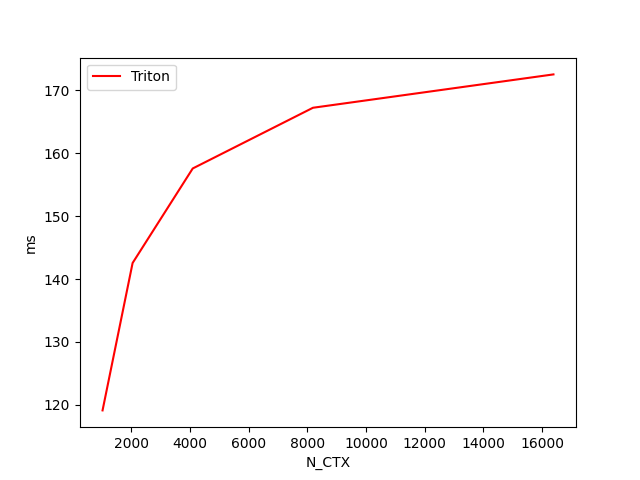
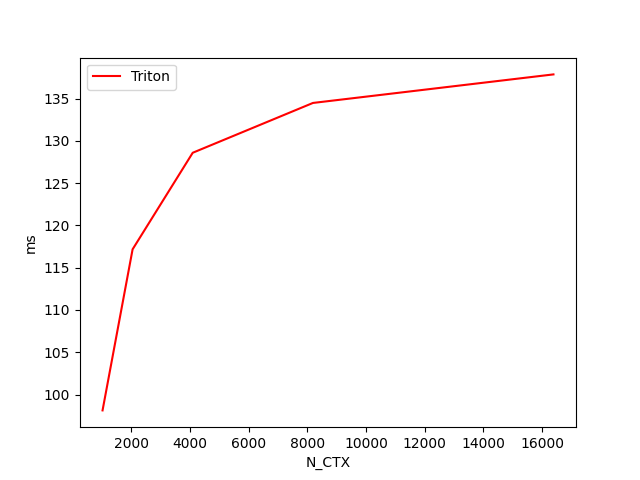
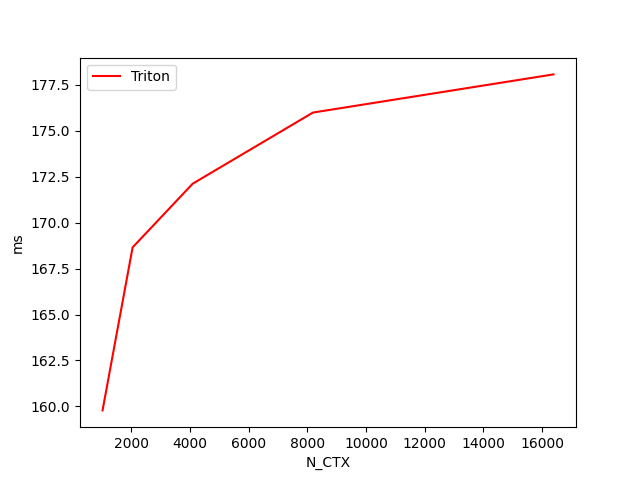
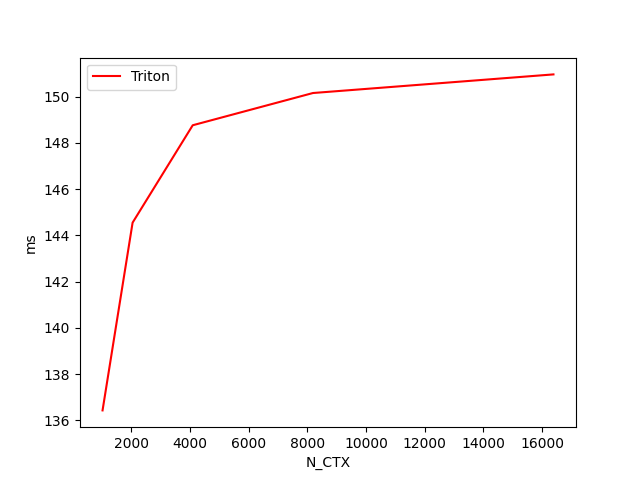
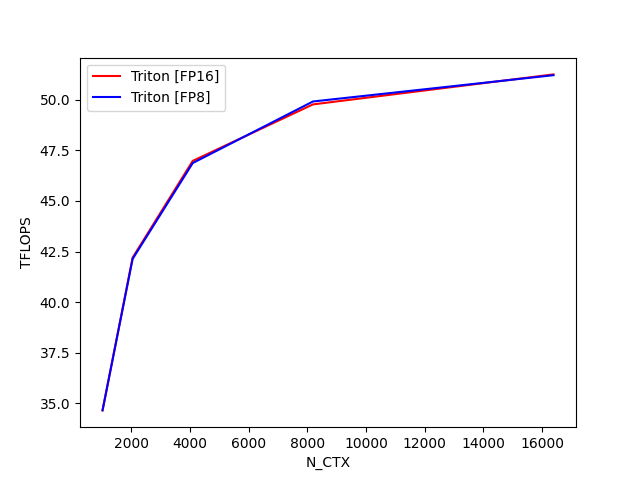
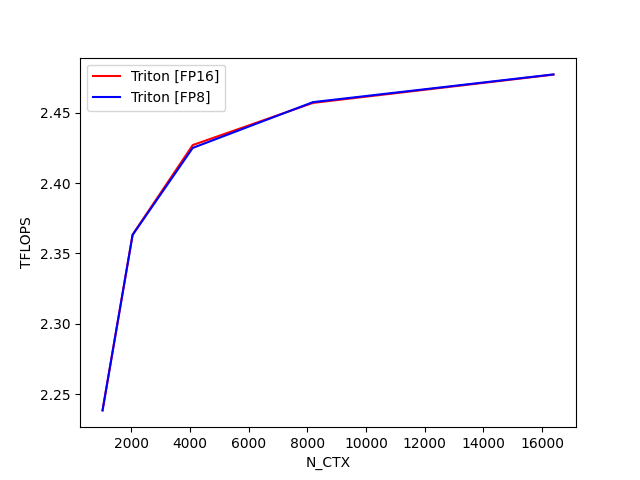
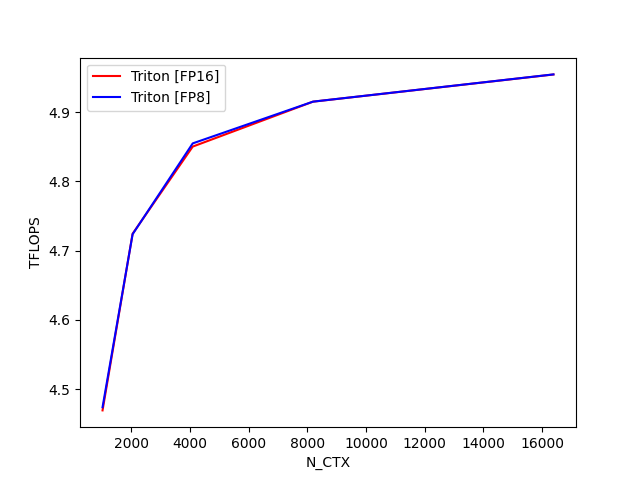
fused-attention-batch4-head32-d64-fwd-causal=True-warp_specialize=False:
N_CTX Triton [FP16] (TFLOPS) Triton [FP8] (TFLOPS)
0 1024.0 112.598764 105.932402
1 2048.0 137.200737 129.485618
2 4096.0 151.262805 146.464278
3 8192.0 159.778254 154.615018
4 16384.0 165.258849 158.174589
fused-attention-batch4-head32-d64-fwd-causal=False-warp_specialize=False:
N_CTX Triton [FP16] (TFLOPS) Triton [FP8] (TFLOPS)
0 1024.0 142.667239 126.215554
1 2048.0 155.896513 153.440190
2 4096.0 162.252202 153.556653
3 8192.0 164.736668 156.133316
4 16384.0 164.008298 157.460357
fused-attention-batch4-head32-d64-bwd-causal=True-warp_specialize=False:
N_CTX Triton [FP16] (TFLOPS) Triton [FP8] (TFLOPS)
0 1024.0 59.503648 58.676712
1 2048.0 75.723290 75.686133
2 4096.0 87.118541 88.045303
3 8192.0 94.995622 94.837881
4 16384.0 98.021913 97.505640
fused-attention-batch4-head32-d64-bwd-causal=False-warp_specialize=False:
N_CTX Triton [FP16] (TFLOPS) Triton [FP8] (TFLOPS)
0 1024.0 77.868520 76.862412
1 2048.0 87.290405 87.347213
2 4096.0 93.024797 93.896855
3 8192.0 96.542151 97.356228
4 16384.0 99.045904 98.913153
fused-attention-batch4-head32-d128-fwd-causal=True-warp_specialize=False:
N_CTX Triton [FP16] (TFLOPS) Triton [FP8] (TFLOPS)
0 1024.0 121.903817 32.469425
1 2048.0 147.221798 131.136032
2 4096.0 164.411295 146.354944
3 8192.0 173.818963 154.662130
4 16384.0 177.155884 159.521892
fused-attention-batch4-head32-d128-fwd-causal=False-warp_specialize=False:
N_CTX Triton [FP16] (TFLOPS) Triton [FP8] (TFLOPS)
0 1024.0 161.864118 136.810701
1 2048.0 172.110783 149.138174
2 4096.0 174.542082 156.849266
3 8192.0 180.154245 159.504115
4 16384.0 179.035295 160.496527
fused-attention-batch4-head32-d128-bwd-causal=True-warp_specialize=False:
N_CTX Triton [FP16] (TFLOPS) Triton [FP8] (TFLOPS)
0 1024.0 2.368058 2.370333
1 2048.0 2.481194 2.479526
2 4096.0 2.546903 2.543949
3 8192.0 2.572900 2.573930
4 16384.0 2.591162 2.591536
fused-attention-batch4-head32-d128-bwd-causal=False-warp_specialize=False:
N_CTX Triton [FP16] (TFLOPS) Triton [FP8] (TFLOPS)
0 1024.0 2.375804 2.374930
1 2048.0 2.424996 2.423000
2 4096.0 2.455888 2.455601
3 8192.0 2.469090 2.468957
4 16384.0 2.475942 2.475773
import pytest
import torch
import os
import triton
import triton.language as tl
from triton.tools.tensor_descriptor import TensorDescriptor
DEVICE = triton.runtime.driver.active.get_active_torch_device()
def is_hip():
return triton.runtime.driver.active.get_current_target().backend == "hip"
def is_cuda():
return triton.runtime.driver.active.get_current_target().backend == "cuda"
def supports_host_descriptor():
return is_cuda() and torch.cuda.get_device_capability()[0] >= 9
def is_blackwell():
return is_cuda() and torch.cuda.get_device_capability()[0] == 10
def is_hopper():
return is_cuda() and torch.cuda.get_device_capability()[0] == 9
@triton.jit
def _attn_fwd_inner(acc, l_i, m_i, q, #
desc_k, desc_v, #
offset_y, dtype: tl.constexpr, start_m, qk_scale, #
BLOCK_M: tl.constexpr, HEAD_DIM: tl.constexpr, BLOCK_N: tl.constexpr, #
STAGE: tl.constexpr, offs_m: tl.constexpr, offs_n: tl.constexpr, #
N_CTX: tl.constexpr, warp_specialize: tl.constexpr, IS_HOPPER: tl.constexpr):
# range of values handled by this stage
if STAGE == 1:
lo, hi = 0, start_m * BLOCK_M
elif STAGE == 2:
lo, hi = start_m * BLOCK_M, (start_m + 1) * BLOCK_M
lo = tl.multiple_of(lo, BLOCK_M)
# causal = False
else:
lo, hi = 0, N_CTX
offsetk_y = offset_y + lo
if dtype == tl.float8e5:
offsetv_y = offset_y * HEAD_DIM + lo
else:
offsetv_y = offset_y + lo
# loop over k, v and update accumulator
for start_n in tl.range(lo, hi, BLOCK_N, warp_specialize=warp_specialize):
start_n = tl.multiple_of(start_n, BLOCK_N)
# -- compute qk ----
k = desc_k.load([offsetk_y, 0]).T
qk = tl.dot(q, k)
if STAGE == 2:
mask = offs_m[:, None] >= (start_n + offs_n[None, :])
qk = qk * qk_scale + tl.where(mask, 0, -1.0e6)
m_ij = tl.maximum(m_i, tl.max(qk, 1))
qk -= m_ij[:, None]
else:
m_ij = tl.maximum(m_i, tl.max(qk, 1) * qk_scale)
qk = qk * qk_scale - m_ij[:, None]
p = tl.math.exp2(qk)
# -- compute correction factor
alpha = tl.math.exp2(m_i - m_ij)
l_ij = tl.sum(p, 1)
# -- update output accumulator --
if not IS_HOPPER and warp_specialize and BLOCK_M == 128 and HEAD_DIM == 128:
BM: tl.constexpr = acc.shape[0]
BN: tl.constexpr = acc.shape[1]
acc0, acc1 = acc.reshape([BM, 2, BN // 2]).permute(0, 2, 1).split()
acc0 = acc0 * alpha[:, None]
acc1 = acc1 * alpha[:, None]
acc = tl.join(acc0, acc1).permute(0, 2, 1).reshape([BM, BN])
else:
acc = acc * alpha[:, None]
# prepare p and v for the dot
if dtype == tl.float8e5:
v = desc_v.load([0, offsetv_y]).T
else:
v = desc_v.load([offsetv_y, 0])
p = p.to(dtype)
# note that this non transposed v for FP8 is only supported on Blackwell
acc = tl.dot(p, v, acc)
# update m_i and l_i
# place this at the end of the loop to reduce register pressure
l_i = l_i * alpha + l_ij
m_i = m_ij
offsetk_y += BLOCK_N
offsetv_y += BLOCK_N
return acc, l_i, m_i
def _host_descriptor_pre_hook(nargs):
BLOCK_M = nargs["BLOCK_M"]
BLOCK_N = nargs["BLOCK_N"]
HEAD_DIM = nargs["HEAD_DIM"]
if not isinstance(nargs["desc_q"], TensorDescriptor):
return
nargs["desc_q"].block_shape = [BLOCK_M, HEAD_DIM]
if nargs["FP8_OUTPUT"]:
nargs["desc_v"].block_shape = [HEAD_DIM, BLOCK_N]
else:
nargs["desc_v"].block_shape = [BLOCK_N, HEAD_DIM]
nargs["desc_k"].block_shape = [BLOCK_N, HEAD_DIM]
nargs["desc_o"].block_shape = [BLOCK_M, HEAD_DIM]
if is_hip():
NUM_STAGES_OPTIONS = [1]
elif supports_host_descriptor():
NUM_STAGES_OPTIONS = [2, 3, 4]
else:
NUM_STAGES_OPTIONS = [2, 3, 4]
configs = [
triton.Config({'BLOCK_M': BM, 'BLOCK_N': BN}, num_stages=s, num_warps=w, pre_hook=_host_descriptor_pre_hook) \
for BM in [64, 128]\
for BN in [32, 64, 128]\
for s in NUM_STAGES_OPTIONS \
for w in [4, 8]\
]
if "PYTEST_VERSION" in os.environ:
# Use a single config in testing for reproducibility
configs = [
triton.Config(dict(BLOCK_M=128, BLOCK_N=64), num_stages=2, num_warps=4, pre_hook=_host_descriptor_pre_hook),
]
def keep(conf):
BLOCK_M = conf.kwargs["BLOCK_M"]
BLOCK_N = conf.kwargs["BLOCK_N"]
return not (is_cuda() and torch.cuda.get_device_capability()[0] == 9 and BLOCK_M * BLOCK_N < 128 * 128
and conf.num_warps == 8)
def prune_invalid_configs(configs, named_args, **kwargs):
N_CTX = kwargs["N_CTX"]
STAGE = kwargs["STAGE"]
# Filter out configs where BLOCK_M > N_CTX
# Filter out configs where BLOCK_M < BLOCK_N when causal is True
return [
conf for conf in configs if conf.kwargs.get("BLOCK_M", 0) <= N_CTX and (
conf.kwargs.get("BLOCK_M", 0) >= conf.kwargs.get("BLOCK_N", 0) or STAGE == 1)
]
@triton.jit
def _maybe_make_tensor_desc(desc_or_ptr, shape, strides, block_shape):
if isinstance(desc_or_ptr, tl.tensor_descriptor):
return desc_or_ptr
else:
return tl.make_tensor_descriptor(desc_or_ptr, shape, strides, block_shape)
@triton.autotune(configs=list(filter(keep, configs)), key=["N_CTX", "HEAD_DIM", "FP8_OUTPUT", "warp_specialize"],
prune_configs_by={'early_config_prune': prune_invalid_configs})
@triton.jit
def _attn_fwd(sm_scale, M, #
Z, H, desc_q, desc_k, desc_v, desc_o, N_CTX, #
HEAD_DIM: tl.constexpr, #
BLOCK_M: tl.constexpr, #
BLOCK_N: tl.constexpr, #
FP8_OUTPUT: tl.constexpr, #
STAGE: tl.constexpr, #
warp_specialize: tl.constexpr, #
IS_HOPPER: tl.constexpr, #
):
dtype = tl.float8e5 if FP8_OUTPUT else tl.float16
tl.static_assert(BLOCK_N <= HEAD_DIM)
start_m = tl.program_id(0)
off_hz = tl.program_id(1)
off_z = off_hz // H
off_h = off_hz % H
y_dim = Z * H * N_CTX
desc_q = _maybe_make_tensor_desc(desc_q, shape=[y_dim, HEAD_DIM], strides=[HEAD_DIM, 1],
block_shape=[BLOCK_M, HEAD_DIM])
if FP8_OUTPUT:
desc_v = _maybe_make_tensor_desc(desc_v, shape=[HEAD_DIM, y_dim], strides=[N_CTX, 1],
block_shape=[HEAD_DIM, BLOCK_N])
else:
desc_v = _maybe_make_tensor_desc(desc_v, shape=[y_dim, HEAD_DIM], strides=[HEAD_DIM, 1],
block_shape=[BLOCK_N, HEAD_DIM])
desc_k = _maybe_make_tensor_desc(desc_k, shape=[y_dim, HEAD_DIM], strides=[HEAD_DIM, 1],
block_shape=[BLOCK_N, HEAD_DIM])
desc_o = _maybe_make_tensor_desc(desc_o, shape=[y_dim, HEAD_DIM], strides=[HEAD_DIM, 1],
block_shape=[BLOCK_M, HEAD_DIM])
offset_y = off_z * (N_CTX * H) + off_h * N_CTX
qo_offset_y = offset_y + start_m * BLOCK_M
# initialize offsets
offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
offs_n = tl.arange(0, BLOCK_N)
# initialize pointer to m and l
m_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float("inf")
l_i = tl.zeros([BLOCK_M], dtype=tl.float32) + 1.0
acc = tl.zeros([BLOCK_M, HEAD_DIM], dtype=tl.float32)
# load scales
qk_scale = sm_scale
qk_scale *= 1.44269504 # 1/log(2)
# load q: it will stay in SRAM throughout
q = desc_q.load([qo_offset_y, 0])
# stage 1: off-band
# For causal = True, STAGE = 3 and _attn_fwd_inner gets 1 as its STAGE
# For causal = False, STAGE = 1, and _attn_fwd_inner gets 3 as its STAGE
if STAGE & 1:
acc, l_i, m_i = _attn_fwd_inner(acc, l_i, m_i, q, #
desc_k, desc_v, #
offset_y, dtype, start_m, qk_scale, #
BLOCK_M, HEAD_DIM, BLOCK_N, #
4 - STAGE, offs_m, offs_n, N_CTX, #
warp_specialize, IS_HOPPER)
# stage 2: on-band
if STAGE & 2:
acc, l_i, m_i = _attn_fwd_inner(acc, l_i, m_i, q, #
desc_k, desc_v, #
offset_y, dtype, start_m, qk_scale, #
BLOCK_M, HEAD_DIM, BLOCK_N, #
2, offs_m, offs_n, N_CTX, #
warp_specialize, IS_HOPPER)
# epilogue
m_i += tl.math.log2(l_i)
acc = acc / l_i[:, None]
m_ptrs = M + off_hz * N_CTX + offs_m
tl.store(m_ptrs, m_i)
desc_o.store([qo_offset_y, 0], acc.to(dtype))
@triton.jit
def _attn_bwd_preprocess(O, DO, #
Delta, #
Z, H, N_CTX, #
BLOCK_M: tl.constexpr, HEAD_DIM: tl.constexpr #
):
off_m = tl.program_id(0) * BLOCK_M + tl.arange(0, BLOCK_M)
off_hz = tl.program_id(1)
off_n = tl.arange(0, HEAD_DIM)
# load
o = tl.load(O + off_hz * HEAD_DIM * N_CTX + off_m[:, None] * HEAD_DIM + off_n[None, :])
do = tl.load(DO + off_hz * HEAD_DIM * N_CTX + off_m[:, None] * HEAD_DIM + off_n[None, :]).to(tl.float32)
delta = tl.sum(o * do, axis=1)
# write-back
tl.store(Delta + off_hz * N_CTX + off_m, delta)
# The main inner-loop logic for computing dK and dV.
@triton.jit
def _attn_bwd_dkdv(dk, dv, #
Q, k, v, sm_scale, #
DO, #
M, D, #
# shared by Q/K/V/DO.
stride_tok, stride_d, #
H, N_CTX, BLOCK_M1: tl.constexpr, #
BLOCK_N1: tl.constexpr, #
HEAD_DIM: tl.constexpr, #
# Filled in by the wrapper.
start_n, start_m, num_steps, #
MASK: tl.constexpr):
offs_m = start_m + tl.arange(0, BLOCK_M1)
offs_n = start_n + tl.arange(0, BLOCK_N1)
offs_k = tl.arange(0, HEAD_DIM)
qT_ptrs = Q + offs_m[None, :] * stride_tok + offs_k[:, None] * stride_d
do_ptrs = DO + offs_m[:, None] * stride_tok + offs_k[None, :] * stride_d
# BLOCK_N1 must be a multiple of BLOCK_M1, otherwise the code wouldn't work.
tl.static_assert(BLOCK_N1 % BLOCK_M1 == 0)
curr_m = start_m
step_m = BLOCK_M1
for blk_idx in range(num_steps):
qT = tl.load(qT_ptrs)
# Load m before computing qk to reduce pipeline stall.
offs_m = curr_m + tl.arange(0, BLOCK_M1)
m = tl.load(M + offs_m)
qkT = tl.dot(k, qT)
pT = tl.math.exp2(qkT - m[None, :])
# Autoregressive masking.
if MASK:
mask = (offs_m[None, :] >= offs_n[:, None])
pT = tl.where(mask, pT, 0.0)
do = tl.load(do_ptrs)
# Compute dV.
ppT = pT
ppT = ppT.to(tl.float16)
dv += tl.dot(ppT, do)
# D (= delta) is pre-divided by ds_scale.
Di = tl.load(D + offs_m)
# Compute dP and dS.
dpT = tl.dot(v, tl.trans(do)).to(tl.float32)
dsT = pT * (dpT - Di[None, :])
dsT = dsT.to(tl.float16)
dk += tl.dot(dsT, tl.trans(qT))
# Increment pointers.
curr_m += step_m
qT_ptrs += step_m * stride_tok
do_ptrs += step_m * stride_tok
return dk, dv
# the main inner-loop logic for computing dQ
@triton.jit
def _attn_bwd_dq(dq, q, K, V, #
do, m, D,
# shared by Q/K/V/DO.
stride_tok, stride_d, #
H, N_CTX, #
BLOCK_M2: tl.constexpr, #
BLOCK_N2: tl.constexpr, #
HEAD_DIM: tl.constexpr,
# Filled in by the wrapper.
start_m, start_n, num_steps, #
MASK: tl.constexpr):
offs_m = start_m + tl.arange(0, BLOCK_M2)
offs_n = start_n + tl.arange(0, BLOCK_N2)
offs_k = tl.arange(0, HEAD_DIM)
kT_ptrs = K + offs_n[None, :] * stride_tok + offs_k[:, None] * stride_d
vT_ptrs = V + offs_n[None, :] * stride_tok + offs_k[:, None] * stride_d
# D (= delta) is pre-divided by ds_scale.
Di = tl.load(D + offs_m)
# BLOCK_M2 must be a multiple of BLOCK_N2, otherwise the code wouldn't work.
tl.static_assert(BLOCK_M2 % BLOCK_N2 == 0)
curr_n = start_n
step_n = BLOCK_N2
for blk_idx in range(num_steps):
kT = tl.load(kT_ptrs)
vT = tl.load(vT_ptrs)
qk = tl.dot(q, kT)
p = tl.math.exp2(qk - m)
# Autoregressive masking.
if MASK:
offs_n = curr_n + tl.arange(0, BLOCK_N2)
mask = (offs_m[:, None] >= offs_n[None, :])
p = tl.where(mask, p, 0.0)
# Compute dP and dS.
dp = tl.dot(do, vT).to(tl.float32)
ds = p * (dp - Di[:, None])
ds = ds.to(tl.float16)
# Compute dQ.
# NOTE: We need to de-scale dq in the end, because kT was pre-scaled.
dq += tl.dot(ds, tl.trans(kT))
# Increment pointers.
curr_n += step_n
kT_ptrs += step_n * stride_tok
vT_ptrs += step_n * stride_tok
return dq
@triton.jit
def _attn_bwd(Q, K, V, sm_scale, #
DO, #
DQ, DK, DV, #
M, D,
# shared by Q/K/V/DO.
stride_z, stride_h, stride_tok, stride_d, #
H, N_CTX, #
BLOCK_M1: tl.constexpr, #
BLOCK_N1: tl.constexpr, #
BLOCK_M2: tl.constexpr, #
BLOCK_N2: tl.constexpr, #
BLK_SLICE_FACTOR: tl.constexpr, #
HEAD_DIM: tl.constexpr, #
CAUSAL: tl.constexpr):
LN2: tl.constexpr = 0.6931471824645996 # = ln(2)
bhid = tl.program_id(2)
off_chz = (bhid * N_CTX).to(tl.int64)
adj = (stride_h * (bhid % H) + stride_z * (bhid // H)).to(tl.int64)
pid = tl.program_id(0)
# offset pointers for batch/head
Q += adj
K += adj
V += adj
DO += adj
DQ += adj
DK += adj
DV += adj
M += off_chz
D += off_chz
# load scales
offs_k = tl.arange(0, HEAD_DIM)
start_n = pid * BLOCK_N1
start_m = 0
MASK_BLOCK_M1: tl.constexpr = BLOCK_M1 // BLK_SLICE_FACTOR
offs_n = start_n + tl.arange(0, BLOCK_N1)
dv = tl.zeros([BLOCK_N1, HEAD_DIM], dtype=tl.float32)
dk = tl.zeros([BLOCK_N1, HEAD_DIM], dtype=tl.float32)
# load K and V: they stay in SRAM throughout the inner loop.
k = tl.load(K + offs_n[:, None] * stride_tok + offs_k[None, :] * stride_d)
v = tl.load(V + offs_n[:, None] * stride_tok + offs_k[None, :] * stride_d)
if CAUSAL:
start_m = start_n
num_steps = BLOCK_N1 // MASK_BLOCK_M1
dk, dv = _attn_bwd_dkdv(dk, dv, #
Q, k, v, sm_scale, #
DO, #
M, D, #
stride_tok, stride_d, #
H, N_CTX, #
MASK_BLOCK_M1, BLOCK_N1, HEAD_DIM, #
start_n, start_m, num_steps, #
MASK=True, #
)
start_m += num_steps * MASK_BLOCK_M1
# Compute dK and dV for non-masked blocks.
num_steps = (N_CTX - start_m) // BLOCK_M1
dk, dv = _attn_bwd_dkdv( #
dk, dv, #
Q, k, v, sm_scale, #
DO, #
M, D, #
stride_tok, stride_d, #
H, N_CTX, #
BLOCK_M1, BLOCK_N1, HEAD_DIM, #
start_n, start_m, num_steps, #
MASK=False, #
)
dv_ptrs = DV + offs_n[:, None] * stride_tok + offs_k[None, :] * stride_d
tl.store(dv_ptrs, dv)
# Write back dK.
dk *= sm_scale
dk_ptrs = DK + offs_n[:, None] * stride_tok + offs_k[None, :] * stride_d
tl.store(dk_ptrs, dk)
# THIS BLOCK DOES DQ:
start_m = pid * BLOCK_M2
start_n = 0
num_steps = N_CTX // BLOCK_N2
MASK_BLOCK_N2: tl.constexpr = BLOCK_N2 // BLK_SLICE_FACTOR
offs_m = start_m + tl.arange(0, BLOCK_M2)
q = tl.load(Q + offs_m[:, None] * stride_tok + offs_k[None, :] * stride_d)
dq = tl.zeros([BLOCK_M2, HEAD_DIM], dtype=tl.float32)
do = tl.load(DO + offs_m[:, None] * stride_tok + offs_k[None, :] * stride_d)
m = tl.load(M + offs_m)
m = m[:, None]
if CAUSAL:
# Compute dQ for masked (diagonal) blocks.
# NOTE: This code scans each row of QK^T backward (from right to left,
# but inside each call to _attn_bwd_dq, from left to right), but that's
# not due to anything important. I just wanted to reuse the loop
# structure for dK & dV above as much as possible.
end_n = start_m + BLOCK_M2
num_steps = BLOCK_M2 // MASK_BLOCK_N2
dq = _attn_bwd_dq(dq, q, K, V, #
do, m, D, #
stride_tok, stride_d, #
H, N_CTX, #
BLOCK_M2, MASK_BLOCK_N2, HEAD_DIM, #
start_m, end_n - num_steps * MASK_BLOCK_N2, num_steps, #
MASK=True, #
)
end_n -= num_steps * MASK_BLOCK_N2
# stage 2
num_steps = end_n // BLOCK_N2
start_n = end_n - num_steps * BLOCK_N2
dq = _attn_bwd_dq(dq, q, K, V, #
do, m, D, #
stride_tok, stride_d, #
H, N_CTX, #
BLOCK_M2, BLOCK_N2, HEAD_DIM, #
start_m, start_n, num_steps, #
MASK=False, #
)
# Write back dQ.
dq_ptrs = DQ + offs_m[:, None] * stride_tok + offs_k[None, :] * stride_d
dq *= LN2
tl.store(dq_ptrs, dq)
class _attention(torch.autograd.Function):
@staticmethod
def forward(ctx, q, k, v, causal, sm_scale, warp_specialize=True):
# shape constraints
HEAD_DIM_Q, HEAD_DIM_K = q.shape[-1], k.shape[-1]
# when v is in float8_e5m2 it is transposed.
HEAD_DIM_V = v.shape[-1]
assert HEAD_DIM_Q == HEAD_DIM_K and HEAD_DIM_K == HEAD_DIM_V
assert HEAD_DIM_K in {16, 32, 64, 128, 256}
o = torch.empty_like(q)
stage = 3 if causal else 1
extra_kern_args = {}
# Tuning for AMD target
if is_hip():
waves_per_eu = 3 if HEAD_DIM_K <= 64 else 2
extra_kern_args = {"waves_per_eu": waves_per_eu, "allow_flush_denorm": True}
M = torch.empty((q.shape[0], q.shape[1], q.shape[2]), device=q.device, dtype=torch.float32)
# Use device_descriptor for Hopper + warpspec.
if supports_host_descriptor() and not (is_hopper() and warp_specialize):
# Note that on Hopper we cannot perform a FP8 dot with a non-transposed second tensor
y_dim = q.shape[0] * q.shape[1] * q.shape[2]
dummy_block = [1, 1]
desc_q = TensorDescriptor(q, shape=[y_dim, HEAD_DIM_K], strides=[HEAD_DIM_K, 1], block_shape=dummy_block)
if q.dtype == torch.float8_e5m2:
desc_v = TensorDescriptor(v, shape=[HEAD_DIM_K, y_dim], strides=[q.shape[2], 1],
block_shape=dummy_block)
else:
desc_v = TensorDescriptor(v, shape=[y_dim, HEAD_DIM_K], strides=[HEAD_DIM_K, 1],
block_shape=dummy_block)
desc_k = TensorDescriptor(k, shape=[y_dim, HEAD_DIM_K], strides=[HEAD_DIM_K, 1], block_shape=dummy_block)
desc_o = TensorDescriptor(o, shape=[y_dim, HEAD_DIM_K], strides=[HEAD_DIM_K, 1], block_shape=dummy_block)
else:
desc_q = q
desc_v = v
desc_k = k
desc_o = o
def alloc_fn(size: int, align: int, _):
return torch.empty(size, dtype=torch.int8, device="cuda")
triton.set_allocator(alloc_fn)
def grid(META):
return (triton.cdiv(q.shape[2], META["BLOCK_M"]), q.shape[0] * q.shape[1], 1)
ctx.grid = grid
if is_blackwell() and warp_specialize:
if HEAD_DIM_K == 128 and q.dtype == torch.float16:
extra_kern_args["maxnreg"] = 168
else:
extra_kern_args["maxnreg"] = 80
_attn_fwd[grid](
sm_scale, M, #
q.shape[0], q.shape[1], #
desc_q, desc_k, desc_v, desc_o, #
N_CTX=q.shape[2], #
HEAD_DIM=HEAD_DIM_K, #
FP8_OUTPUT=q.dtype == torch.float8_e5m2, #
STAGE=stage, #
warp_specialize=warp_specialize, #
IS_HOPPER=is_hopper(), #
**extra_kern_args)
ctx.save_for_backward(q, k, v, o, M)
ctx.sm_scale = sm_scale
ctx.HEAD_DIM = HEAD_DIM_K
ctx.causal = causal
return o
@staticmethod
def backward(ctx, do):
q, k, v, o, M = ctx.saved_tensors
assert do.is_contiguous()
assert q.stride() == k.stride() == v.stride() == o.stride() == do.stride()
dq = torch.empty_like(q)
dk = torch.empty_like(k)
dv = torch.empty_like(v)
BATCH, N_HEAD, N_CTX = q.shape[:3]
PRE_BLOCK = 128
NUM_WARPS, NUM_STAGES = 4, 5
BLOCK_M1, BLOCK_N1, BLOCK_M2, BLOCK_N2 = 32, 128, 128, 32
BLK_SLICE_FACTOR = 2
RCP_LN2 = 1.4426950408889634 # = 1.0 / ln(2)
arg_k = k
arg_k = arg_k * (ctx.sm_scale * RCP_LN2)
PRE_BLOCK = 128
assert N_CTX % PRE_BLOCK == 0
pre_grid = (N_CTX // PRE_BLOCK, BATCH * N_HEAD)
delta = torch.empty_like(M)
_attn_bwd_preprocess[pre_grid](
o, do, #
delta, #
BATCH, N_HEAD, N_CTX, #
BLOCK_M=PRE_BLOCK, HEAD_DIM=ctx.HEAD_DIM #
)
grid = (N_CTX // BLOCK_N1, 1, BATCH * N_HEAD)
_attn_bwd[grid](
q, arg_k, v, ctx.sm_scale, do, dq, dk, dv, #
M, delta, #
q.stride(0), q.stride(1), q.stride(2), q.stride(3), #
N_HEAD, N_CTX, #
BLOCK_M1=BLOCK_M1, BLOCK_N1=BLOCK_N1, #
BLOCK_M2=BLOCK_M2, BLOCK_N2=BLOCK_N2, #
BLK_SLICE_FACTOR=BLK_SLICE_FACTOR, #
HEAD_DIM=ctx.HEAD_DIM, #
num_warps=NUM_WARPS, #
num_stages=NUM_STAGES, #
CAUSAL=ctx.causal, #
)
return dq, dk, dv, None, None, None, None
attention = _attention.apply
TORCH_HAS_FP8 = hasattr(torch, 'float8_e5m2')
@pytest.mark.parametrize("Z", [1, 4])
@pytest.mark.parametrize("H", [2, 48])
@pytest.mark.parametrize("N_CTX", [128, 1024, (2 if is_hip() else 4) * 1024])
@pytest.mark.parametrize("HEAD_DIM", [64, 128])
@pytest.mark.parametrize("causal", [False, True])
@pytest.mark.parametrize("warp_specialize", [False, True] if is_blackwell() else [False])
@pytest.mark.parametrize("mode", ["fwd", "bwd"])
@pytest.mark.parametrize("provider", ["triton-fp16"] + (["triton-fp8"] if TORCH_HAS_FP8 else []))
def test_op(Z, H, N_CTX, HEAD_DIM, causal, warp_specialize, mode, provider, dtype=torch.float16):
if mode == "fwd" and "fp16" in provider:
pytest.skip("Avoid running the forward computation twice.")
if mode == "bwd" and "fp8" in provider:
pytest.skip("Backward pass with FP8 is not supported.")
torch.manual_seed(20)
q = (torch.empty((Z, H, N_CTX, HEAD_DIM), dtype=dtype, device=DEVICE).normal_(mean=0.0, std=0.5).requires_grad_())
k = (torch.empty((Z, H, N_CTX, HEAD_DIM), dtype=dtype, device=DEVICE).normal_(mean=0.0, std=0.5).requires_grad_())
v = (torch.empty((Z, H, N_CTX, HEAD_DIM), dtype=dtype, device=DEVICE).normal_(mean=0.0, std=0.5).requires_grad_())
sm_scale = 0.5
# reference implementation
ref_dtype = dtype
if mode == "fwd" and "fp8" in provider:
ref_dtype = torch.float32
q = q.to(ref_dtype)
k = k.to(ref_dtype)
v = v.to(ref_dtype)
M = torch.tril(torch.ones((N_CTX, N_CTX), device=DEVICE))
p = torch.matmul(q, k.transpose(2, 3)) * sm_scale
if causal:
p[:, :, M == 0] = float("-inf")
p = torch.softmax(p.float(), dim=-1)
p = p.to(ref_dtype)
# p = torch.exp(p)
ref_out = torch.matmul(p, v).half()
if mode == "bwd":
dout = torch.randn_like(q)
ref_out.backward(dout)
ref_dv, v.grad = v.grad.clone(), None
ref_dk, k.grad = k.grad.clone(), None
ref_dq, q.grad = q.grad.clone(), None
# triton implementation
if mode == "fwd" and "fp8" in provider:
q = q.to(torch.float8_e5m2)
k = k.to(torch.float8_e5m2)
v = v.permute(0, 1, 3, 2).contiguous()
v = v.permute(0, 1, 3, 2)
v = v.to(torch.float8_e5m2)
tri_out = attention(q, k, v, causal, sm_scale, warp_specialize).half()
if mode == "fwd":
atol = 3 if "fp8" in provider else 1e-2
torch.testing.assert_close(tri_out, ref_out, atol=atol, rtol=0)
return
tri_out.backward(dout)
tri_dv, v.grad = v.grad.clone(), None
tri_dk, k.grad = k.grad.clone(), None
tri_dq, q.grad = q.grad.clone(), None
# compare
torch.testing.assert_close(tri_out, ref_out, atol=1e-2, rtol=0)
rtol = 0.0
# Relative tolerance workaround for known hardware limitation of CDNA2 GPU.
# For details see https://pytorch.org/docs/stable/notes/numerical_accuracy.html#reduced-precision-fp16-and-bf16-gemms-and-convolutions-on-amd-instinct-mi200-devices
if torch.version.hip is not None and triton.runtime.driver.active.get_current_target().arch == "gfx90a":
rtol = 1e-2
torch.testing.assert_close(tri_dv, ref_dv, atol=1e-2, rtol=rtol)
torch.testing.assert_close(tri_dk, ref_dk, atol=1e-2, rtol=rtol)
torch.testing.assert_close(tri_dq, ref_dq, atol=1e-2, rtol=rtol)
try:
from flash_attn.flash_attn_interface import \
flash_attn_qkvpacked_func as flash_attn_func
HAS_FLASH = True
except BaseException:
HAS_FLASH = False
TORCH_HAS_FP8 = hasattr(torch, 'float8_e5m2')
BATCH, N_HEADS = 4, 32
# vary seq length for fixed head and batch=4
configs = []
for HEAD_DIM in [64, 128]:
for mode in ["fwd", "bwd"]:
for causal in [True, False]:
# Enable warpspec for causal fwd on Hopper
enable_ws = mode == "fwd" and (is_blackwell() or (is_hopper() and not causal))
for warp_specialize in [False, True] if enable_ws else [False]:
configs.append(
triton.testing.Benchmark(
x_names=["N_CTX"],
x_vals=[2**i for i in range(10, 15)],
line_arg="provider",
line_vals=["triton-fp16"] + (["triton-fp8"] if TORCH_HAS_FP8 else []) +
(["flash"] if HAS_FLASH else []),
line_names=["Triton [FP16]"] + (["Triton [FP8]"] if TORCH_HAS_FP8 else []) +
(["Flash-2"] if HAS_FLASH else []),
styles=[("red", "-"), ("blue", "-"), ("green", "-")],
ylabel="TFLOPS",
plot_name=
f"fused-attention-batch{BATCH}-head{N_HEADS}-d{HEAD_DIM}-{mode}-causal={causal}-warp_specialize={warp_specialize}",
args={
"H": N_HEADS,
"BATCH": BATCH,
"HEAD_DIM": HEAD_DIM,
"mode": mode,
"causal": causal,
"warp_specialize": warp_specialize,
},
))
@triton.testing.perf_report(configs)
def bench_flash_attention(BATCH, H, N_CTX, HEAD_DIM, causal, warp_specialize, mode, provider, device=DEVICE):
assert mode in ["fwd", "bwd"]
dtype = torch.float16
if "triton" in provider:
q = torch.randn((BATCH, H, N_CTX, HEAD_DIM), dtype=dtype, device=device, requires_grad=True)
k = torch.randn((BATCH, H, N_CTX, HEAD_DIM), dtype=dtype, device=device, requires_grad=True)
v = torch.randn((BATCH, H, N_CTX, HEAD_DIM), dtype=dtype, device=device, requires_grad=True)
if mode == "fwd" and "fp8" in provider:
q = q.to(torch.float8_e5m2)
k = k.to(torch.float8_e5m2)
v = v.permute(0, 1, 3, 2).contiguous()
v = v.permute(0, 1, 3, 2)
v = v.to(torch.float8_e5m2)
sm_scale = 1.3
fn = lambda: attention(q, k, v, causal, sm_scale, warp_specialize)
if mode == "bwd":
o = fn()
do = torch.randn_like(o)
fn = lambda: o.backward(do, retain_graph=True)
ms = triton.testing.do_bench(fn)
if provider == "flash":
qkv = torch.randn((BATCH, N_CTX, 3, H, HEAD_DIM), dtype=dtype, device=device, requires_grad=True)
fn = lambda: flash_attn_func(qkv, causal=causal)
if mode == "bwd":
o = fn()
do = torch.randn_like(o)
fn = lambda: o.backward(do, retain_graph=True)
ms = triton.testing.do_bench(fn)
flops_per_matmul = 2.0 * BATCH * H * N_CTX * N_CTX * HEAD_DIM
total_flops = 2 * flops_per_matmul
if causal:
total_flops *= 0.5
if mode == "bwd":
total_flops *= 2.5 # 2.0(bwd) + 0.5(recompute)
return total_flops * 1e-12 / (ms * 1e-3)
if __name__ == "__main__":
# only works on post-Ampere GPUs right now
bench_flash_attention.run(save_path=".", print_data=True)
Total running time of the script: (16 minutes 7.013 seconds)